Bruno Beltran
Mathematician, Biophysicist, Programmer

Mathematician, Biophysicist, Programmer
Click the links below to view some of my more popular projects.
For access to unpublished code, please see my Github or contact me.
My research has spanned several fields, from semigroup theory to bacterial cell size control, and from statistics to modeling chromatin organization.
Below, I highlight some recent projects:
(click to see full size)
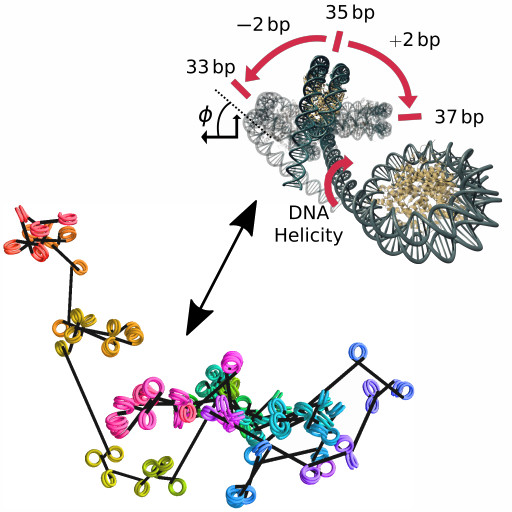
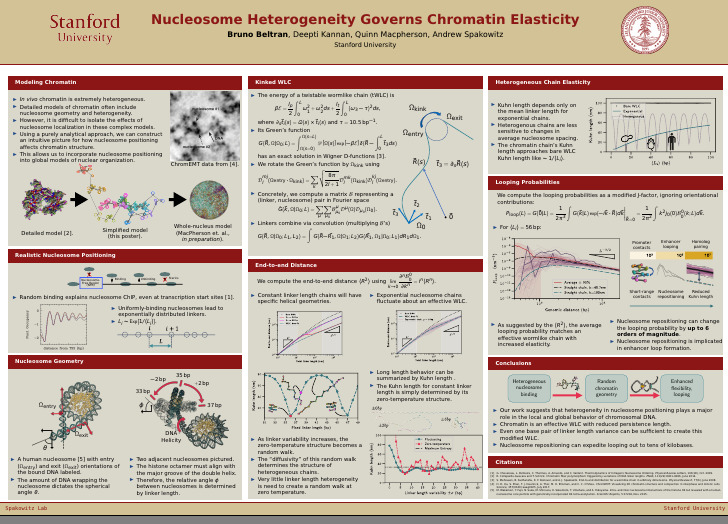
It is now understood that chromatin's structure in the nucleus is more like disorganized "beads-on-a-spring" than the "30nm fiber" historically seen by electron microscopy. We analytically compute the Greens function for a diffusion in SO(3) subordinated to a CTRW (i.e. a wormlike chain with random, rigid kinks). This analytical models demonstrates that heterogeneity in nucleosome spacing drives structural disorder, and that the bulk properties of chromatin can be modulated by repositioning nucleosomes. More details available in the paper.
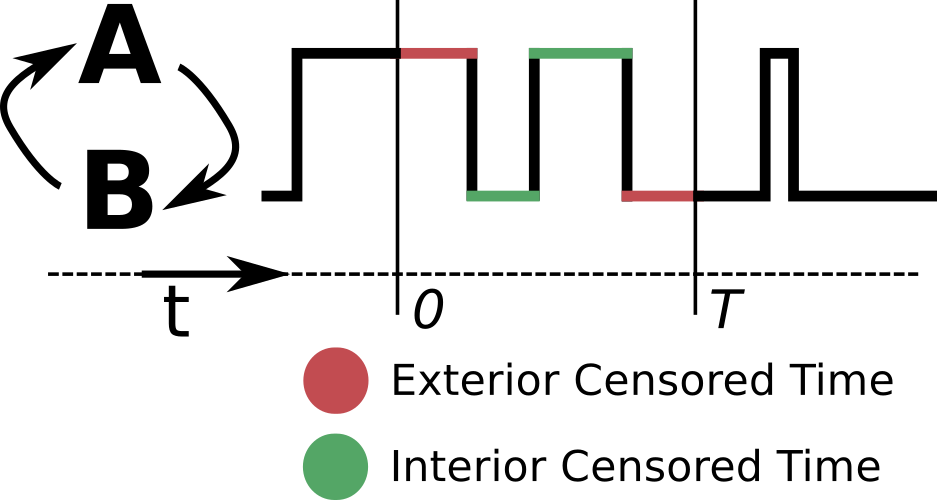
Historically, the Meier-Kaplan correction has been used whenever an experiment measure "lifetimes" that are "right-censored" (meaning you stop observing before the event you're waiting for happens). However, not all right-censored waiting times are correctly treated by the Meier-Kaplan approach. We have developed a generalized framework for easily classifying right-censored waiting times, and a simple, fast algorithm for generating correct survival curves (or histograms) of real measured lifetimes. A Python package implementing these corrections can be found here.
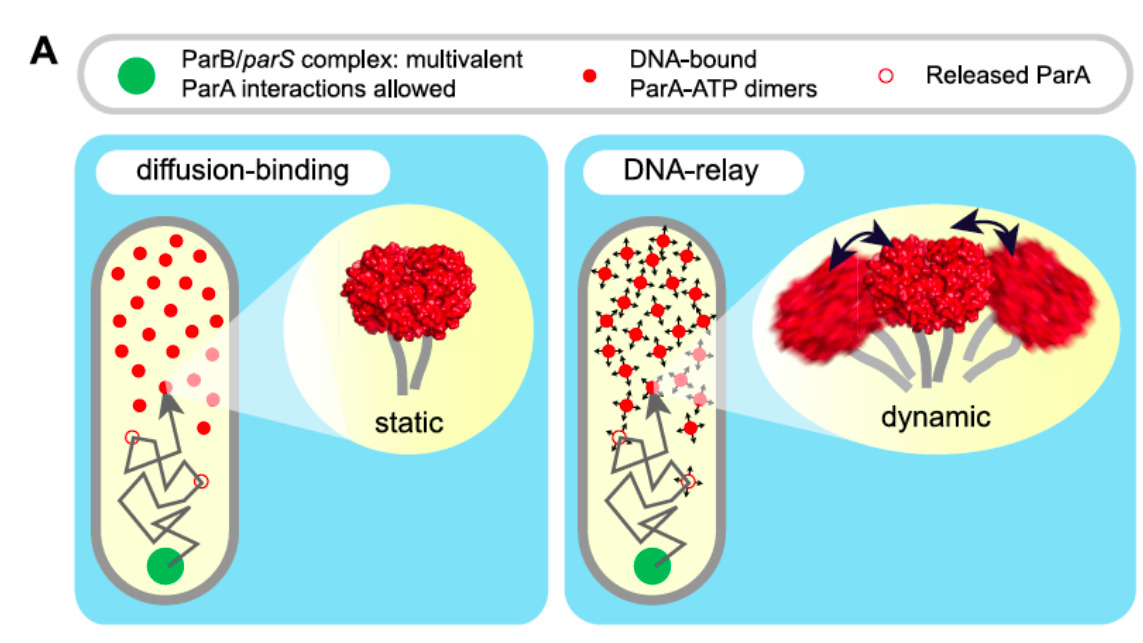
A coarse-grained model of the ParABS plasmid partitioning system shows that Caulobacter crescentus can use it as a heat engine to drive segregation of the new copy of its chromosome before division. The general "burned-bridge" type heat-engine that we describe has now been shown to also drive the canonical plasmid-partitioning behavior of ParABS in E. coli.
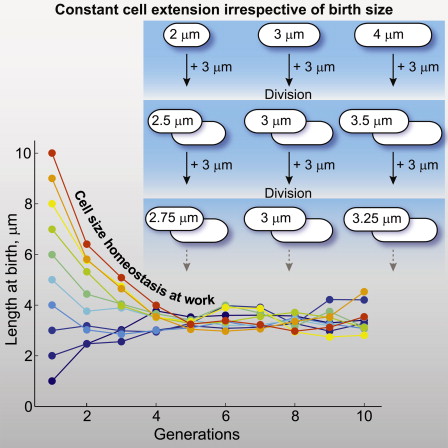
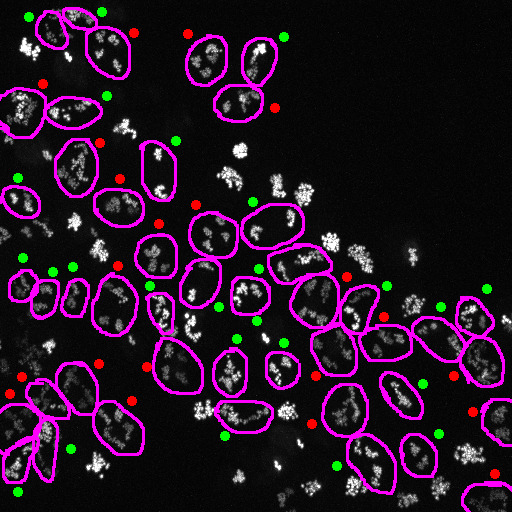
Analysis of high-throughput movies of C. crescentus and E. coli growth were used to show that bacterial populations control their average cell size not by timing how long the cells have lived, not by measuring a specific cell size that triggers division, but via a random process where each cell simply grows the same amount on average. The paper can be found here.
Almost everything that I would normally have made into a blog post is either a coding tutorial (see my code page) or has now become a published paper (see my science page).
However, if you are interested in the philosophy of science, perhaps you'll find something worthwhile here...
Is imprecise language.
Okay, maybe multi-million-dollar misinformation campaigns can also be very effective. But I would argue that imprecise language damaged science in the 20th century at least as much as the cigarette and oil lobbies.
There are innumerable ways that imprecise language can lead to pseudoscience. For one, simple gaffs from prominent scientists can often be enough. After all, if I asked my family back home what the tone of a typical scientist makes them feel, they would probably complain that scientists always seem to want people to know "I am right, whether you like it or not". People can forgive mistakes, but when they feel spoken down to, even the smallest mistakes can be made grounds for complete dismissal of an idea.
On the other hand, I dare anyone to name a single language issue that plagues science more at the turn of the 21st century than attempts to appropriate common words into the scientific parlance (its less-insidious converse: trying to introduce scientific definitions to the public via too-simple analogies, is more well known).
If you need convincing that this is the case, I've provided in what follows three diverse examples of the kinds of issues that arise when common language words are given new, "more rigorous" definitions by scientists. One from the social sciences, one from game theory, and one from quantum mechanics. I close with some of my thoughts about how to prevent these issues in the first place.
I especially try to demonstrate with an example from game theory how trying to come up with scientific definitions of common words tends to lead to incredibly persistent miscommunication, even among other scientists in the same field. However, to see how pernicious this problem can really be, we'll first examine the damage that can be done when the confused party is instead the general public.
For non-scientist readers, hopefully this is a window into one of the many ways in which common journalistic practices from "pop-science" can easily deceive you. For scientist readers, I hope to convince you that if a word is already in common use, and you try to give it a rigorous definition, no matter how well intentioned you may be, or how close that word is to capturing the original colloquial meaning, at best you're going to cause confusion, and at worst you're going to piss people off.
An obvious example of this worst-case has unfortunately already played out with the word "gender". Social scientists now uniformly use this word to refer to the socially-constructed aspects of the ideas colloquially referred to as masculinity and femininity. However, before the 1950s, the word gender was already in use, and referred only to grammatical categories. In many places, for example in the southern United States (where I went to university), this old convention is still the only way the word is commonly used (especially among those above the age of 30).
There is no better way to alienate someone on a topic than to start by trying to convince them that a word they've been using their whole life suddenly has a new definition (entire comedy routines are based off of this fact). While the abuses that continue to be perpetrated towards trans and non-binary peoples in the South are totally inexcusable, I have personally seen countless potential allies (especially religious people) driven away from LGBT+ issues due to simple misunderstandings caused by well-intentioned attempts to change language by fiat.
Had the word chosen for what we now call gender been anything else, maybe something with a Latin root that invokes the idea that it's socially constructed, or maybe something that explicitly intoned an independence from the concept of biological "sex", I posit that any number of needless, hateful internet fights about whether or not there are "only two genders" could have been completely avoided. And if you really think that the people crying that there are "only two genders" are all bigots and never just trying to argue in good faith that we should just use the word gender to mean "chromosome-encoded, biological sex", you, just aren't paying attention.
So, clearly, the choice by sociologists as a scientific community to legitimize this potentially confusing terminology directly fed one of the largest sources of internet hatred in the early 21st century.
But don't think for a second that this is something that can only happen in the "soft" sciences. Non-social scientists often feel immune to this type of problem due to a perception that they are more "rigorous" and so cannot fall into the traps of creating a situation where a well-defined word is more confusing than it is helpful. But as we'll see soon, that is far from the case.
(Disclaimer: thankfully, the sociologist's definition of the word "gender" seems to be on track to become well-accepted within the next generation. I fully support the charge to normalize this word in the public mind, as whatever problems may have occured due to the initial pushback against this usage now pale in comparison to the practical need to adopt a word that can be used by, for example, trans and non-binary people to accurately describe their experiences. Hopefully normalization of this word is the first step to a more compassionate and productive discourse on the positive and negative roles of both masculinity and femininity.
That said, if I could go back to 1955 and talk to John Money, I would plead that he choose a different word.)
If you're already familiar with the Nash equilibrium of the finite iterated prisoner's dilemma, feel free to skip here.
Suppose you're on a game show. A celebrity moderator stands between you and your "opponent". The rules of the game are simple: each turn, you each press one of two buttons. If you both press the "C" button ("C" for "cooperate"), you both get $100,000. If you both press the "D" button ("D" for "defect"), you each get a measly $10,000.
Easy enough? Except that if you betray the other person (by presses "D" when they press "C"), you gain $150,000 instead of $100,000! Now that's a lot of extra money (almost two years of a graduate student's salary, if anyone's asking).

In real life, this could be a reasonably tense game show. With lots of pleading, promises (sometimes broken) and potentially many tears. But suppose now that instead of being out on a stage, with a celebrity host and a cheering crowd, you're instead playing from inside an interrogation room. All you were told about your opponent is that you've never met them. The windows are blacked out and the only contact you have with the outside world is the two buttons in front of you, and a timer above you, telling you how much longer you have to make your final choice.
What should you do?
Suppose your goal is to make as much money as possible, and you've been told there are ten turns. What is the rational thing to do? Is there a "rational" thing to do?
If you've taken microeconomics or read about game theory (or are particularly cynical), you'll recognize that if there was only one turn, you are always "better off" pressing "D". You have no control over what your opponent will do, but we can think about what will happen for each of their two options.
Suppose your opponent presses "C". Then if you press "D", you get $50,000 more than if you press "C"! If they are going to press "D", then you may only get $10,000 for pressing "D", but it's better than the $0 you would get for pressing "C". So in either case you're strictly better off pressing "D".
This is microeconomics's favorite "unintuitive" result. Just like a statistics professor presenting the birthday problem, a econ professor must typically jump through several hoops to convince the class that while they may not think it's "right" to defect and press "D", it is the strictly more "rational" decision. And so we arrive at the definition of "rationality" used in game theory: if there is a choice present that has a reward strictly higher than any other choice, regardless of what the opponent does (a strictly dominant strategy), a "rational" player will always choose such a strictly dominant strategy. In other words, the player is rational if they can follow the train of thought above.
This may seem like a pretty good definition of the word rational. After all, why would a "rational" agent ever do something not in their best interest? That is, however, until you ask how the original game plays out if both players are "rational". Obviously on the last turn, the game is equivalent to the one turn version, so both players will choose "D". But then if the last turn of the game is fixed, the second to last turn is also equivalent to the one-turn case, since the players don't have to take the last turn into consideration (they're both rational and know each other are rational, so they can deduce what the outcome will be for the last turn). So that means only the second-to-last turn matters in isolation, so the players also both choose "D" on the second to last turn, and on the third-to-last turn, and so on and so on.
This may seem like a sneaky argument, but a rigorous version of this analysis exists (it's called "backwards induction"), and it can be used to prove that in any finite (fixed number of turns) prisoner's dilemma, no matter how many turns there are, two "rational" players, for this game theoretic definition of "rational", will always play "D".
And depending on your risk tolerance, this might make some sense intuitively, after all, walking away with with 10*$10,000 is a pretty sweet deal, and maybe better than $0 to some theoretical "rational" agent.
However, changing the game slightly makes this result totally nonsensical to most people

If the prize for both people defecting is only one dollar, you'd be hard pressed to find anyone that would agree that the "rational" choice is to always defect. In fact, almost any other strategy will do better! So is game theory wrong?
Well, of course not, game theory is a mathematical framework, it simply tells us the logical conclusions given the definitions that we have laid out. On the one hand, it could be argued that the fact that the game theoretic version of "rationality" doesn't align with our colloquial understanding of the word is not a problem. After all, as long as we're clear on which version of the word we're using, we should be fine right?
On the other hand, I'm sure it's clear how it can be extremely easy to see how this definition of rationality could be incorrectly used in a headline: "game theory teaches us that betrayal is rational". Anybody who tries to claim that such a headline is purely the fault of a subpar journalist has never tried to teach game theory. When you have to spend most of the class hammering home the ideas that "humans aren't rational", and "that strategy does make the most sense, but it's not technically 'rational', because...", at some point I think you have to realize that the problem is not with the students, but with the choice of words being taught.
Even successful game theorists have been known to accidentally tie themselves into knots trying to explain how to best interpret counterintuitive results on rationality, forgetting that "rational" is just a mathematical concept that we happened to choose an extremely loaded word for, and that game theory does not provide any guidance about what rationality "should" mean, nor about the faculties that govern human reason (the traditional meaning of the word rationality).
A great example of this very issue can be found towards the end of the excellent book by Martin Osborne and Ariel Rubinstein, "A Course in Game Theory". The authors come to such disagreement about how to interpret the experimental result that humans act as if there were an infinite number of turns (i.e., they do not choose to defect immediately) that they include in the book itself a back and forth with each other (starting on page 135). Their disagreement fundamentally boils down to the question of whether or not it makes sense to model human interactions in the finite prisoners dilemma using the methods described above. And, well, of course it doesn't. There's a whole field of economics (behavioral game theory) devoted to how far human reason is from game theory's definition of "rational".
So even scientists are not immune to the dangers of misappropriated words.
And if you think that economics is still too much of a social science to count as an example of word misappropriation by the hard sciences, let's talk about:
While I don't have nearly enough room in a blog post to defend such a thesis, I can't resist writing this, if only to piss off my philosophy of physics friends.
There has been an absolute boatload of human time devoted to explaining (and trying to solve) various problems at the "heart" of quantum mechanics, collectively known as the "foundations of quantum mechanics". If you've heard of the many-worlds interpretation, the Copenhagen interpretation, the measurement problem, or other "paradoxes" of quantum mechanics, you've been exposed to these ideas before.
I think that the whole business of trying to "solve" these paradoxes is just another waste of time that is distracted perfectly good minds from attacking real, useful problems. I think that once you start to carefully frame these problems from within any reasonable, logically consistent model for what science "is", the problems completely go away.
What do I mean by that? And how does it tie into the problem of trying to rigorously define common words?
Let's take the measurement problem for example. People always complain that the quantum wavefunctions needs someone to "measure" them in order to produce "observables". As David Albert recounts to Sean Carroll in Carroll's excellent podcast, even prominent, Nobel-winning physicists like Wigner have been known to speculate totally wacky-sounding ideas in response to this "problem". Even going as far as to claim thing to the effect of "dogs could likely collapse wavefunctions, but mice probably not".
But the framing of the measurement problem itself has a problem. Wikipedia defines the measurement problem as "the problem of how (or whether) wave function collapse occurs".
To explain why this is a silly question, I'll use a simple (if slightly flawed) analogy.
In the theory of polymers, there is the notion of a "Rouse" polymer. Any polymer, when made sufficiently long, will be described well by the "Rouse" polymer model. However, the "Rouse" polymer itself (as a mathematical object) looks like a fractal, random walk through space with infinite energy. Obviously, there is no sense in which a strand of DNA looks like an infinitely jagged fractal path. If we zoom in enough, we will see individual base pairs (and eventually individual atoms) which do not resemble linear fractals in the slightest. However, DNA is a polymer, and sure enough, the Rouse polymer model has been wildly successful at describing its behavior on long length scales.
Similarly, quantum mechanics has been a hugely successful theory, and the mathematical object at its center is known as the wavefunction. This obviously does not have any bearing on whether there "is" such a wavefunction, to which me must actually assign some higher ontological status beyond its mathematical utility for calculating things that we observe in our actual universe.
In this sense, asking whether the wavefunction "actually" collapses makes a category error. The wavefunction that most physicists know and love is a mathematical object, not a physical one. Asking whether it "actually" collapses sneaks in the assumption that it "actually" exists.
So why not go and try to measure it then? Well the real crux of the issue is that it is logically inconsistent to measure the wavefunction directly according to the theory of quantum mechanics. It doesn't even make sense to ask the math that kind of question. Which doesn't mean that it's impossible to ever know whether or not there is a measurable, high-dimensional wave-like that permeates space-time. It just means that if it is possible to ask such a question, it requires a more general theory which we do not currently have.
Until then, people asking whether or not the wavefunction "really" collapses are wasting their time.
But what does this have to do with trying to assign rigorous, scientific meaning to common words? Well, quantum theory is a zoo of such assignments. The most relevant to the measurement problem is the definition of the word "observable".
The definition of a "measurement" in quantum mechanics is typically given to be "anything which is an observable". And while this may seem like a play on words from outside of the theory, it turns out to make sense because in quantum theory, the word "observable" actually has a very specific mathematical definition (a self-adjoint Hermitian operator on a Hilbert space of "states").
I cannot speak to what drove Wigner to postulate that dogs may be capable of "observing" the wavefunction, yet mice not so much. But I can say that if you teach quantum mechanics for long enough, you notice that time and time again, students will come to you with questions about the philosophy of quantum mechanics that accidentally treat this mathematical model of "observables" as corresponding to the intuitive notion of actually performing a physical measurement out in the world.
Most of these students go on to become successful practioners of quantum mechanics, but some unfortunate few end up wasting years of their life unnecessarily pondering silly questions like the "ontological status of measurement".
So what do we do about this issue? We've seen that not being careful about our choice of words can lead to (in vaguely increasing order of insidiousness)
Is the answer really to have better foresight about how our definitions might be misinterpreted? I, for one, don't think so. While it is encumbent on scientists to police themselves to prevent egregiously confusing terms from coming into common use in the first place, no matter how hard you try, you're never going to be able to accurately predict the connotations society as a whole will assign to a word after you start using it in a new way.
Here are a few thoughts from my own personal experience:
Science, at the end of the day, is really just the process by which we map our observations of reality onto the world of mathematics (the persnickety philosopher can find an incoherent rant with more details about what I mean here):

As long as we're living completely on the right side of this diagram (in the world of mathematics) it makes sense to say that "assumptions A, B, and C prove conclusion X". As long as you specify A, B, and C well enough, either "\(A+B+C \Rightarrow X\)"or it doesn't. There is no way for someone to disagree with a valid proof that "\(A+B+C \Rightarrow X\)". Sure, anyone can misunderstand a complicated enough mathematical statement, but anyone that continues to disagreee with valid logic once it's been made clear doesn't deserve to be part of the conversation.
On the other hand, scientific statements tend to be more complicated creatures. Often, they take the form of predictions about new data made using existing data:

Suddenly, there are several levels on which you can disagree with someone. Let's take a concrete example. Say my physical theory is just Newton's gravity (\(T_i\)), and suppose you have some set of measurements, like the initial trajectory of a satellite that you've launched (\(d_\text{existing}\)). If I say to you, "given this initial trajectory, the satellite's orbit will be so-and-so (\(d_\text{new}\)) in two days", there are several ways you can disagree with that statement:
On the other hand, if you accept \(d_\text{existing}\), you accept that \(X_1 \nRightarrow X_2\), and you believe that the physical theory \(T_i\) should hold, then you must agree with my conclusions.
Science is the process by which we select increasingly accurate scientific models.
And this process is entirely based on heuristics.
...you're sure to hear grandiose claims about the stagnation of science and no real substance to back it up. Or at least that's what you'll get if you watch Eric's recently released first podcast episode (I would recommend against).
Potshots aside though, I was pretty flabbergasted by their claim that since the early 1970s, science as a whole has more or less frozen in time, and that academic progress has ground to what amounts to a complete halt. Perhaps I am blinded by young naiveté, but from my perspective several fields (especially biology, which they seem to have it out for in particular) have done nothing but accelerate the pace of their development over the past ten years. From the human genome project to CRISPr, it's hard to deny that advances in our ability to probe and modify our own biology is advancing at an exponential rate even faster than Moore's law. (And this comes just as Moore's law itself is slowing down for the first time since the 70s, the point of time at which Peter and Eric claim the great demise of science began).
So why the pessimism on their part? Well they really do harp on the idea that progress in biology, (after molecular biology was "founded by physicists") never progressed at a pace comparable to that of our understanding of "the atom". They make sure to never pin down exactly what would constitute a "fast" pace of biological discovery, but they make sure to explicitly posit that biology full of "not [as] talented people" as physics.
If you spend any non-zero amount of time at the interface of math, physics, and biology, this is a pattern that you'll see come up over and over again. Physicists (or in Thiel's case, simply self-proclaimed "intellectuals"), always think that with their superior creativity/intelligence/mathematical ability, they can swoop into biology, arguably the most populated area of modern research, and swiftly lay down some kind of simple foundational principles that have managed to elude biologists for the past century.
Invariably, some fraction of these physicists actually do start doing biological research, and quickly find themselves drowning in a sea of protein names, apparently useless acronyms for genes, and systems that require much more specification and have many fewer "universal" properties than they would have anticipated. Most run away before getting very far, but many make non-trivial contributions (after all, its true that typical biologists tend to prefer having other people do their math/modeling for them, so that they have more time to do experiments). That said, only a very few become "card-carrying" biologists, able to hold their own in a conversation with the mythical "real" biologist, whose encyclopaedic knowledge of historical experiments, networks of genes, and post-translational modifications related to their system of interest literally dwarfs even the literature itself, due to years of hearing folkloric, unpublished results through the grapevine.
What separates these "card-carrying" biologists from the physicists that run away? Is it as Eric and Peter would probably suggest, that they have simply become focused on less interesting questions? Have they simply lost their love or ability to do mathematics?
I think what separates the wheat from the chaff is the realization that the fundamental principles of biology have long been well known, just as they have been for physics. Namely:
What the physicists-turned-biologists that I respect will all universally admit is that biology seems to follow what I like to call the "principle of most action": if you think you know the answer to how something is being done by a cell, you are probably missing 10 more key players, several dozen more backup systems, and the part that you think is most important may even be just vestigial.
Is this status quo (that most biological "models" are doomed to fail) just a side effect of biologists not being smart enough to make good models? NO! It's built right into the thing that's being studied. Organisms that spent billions of years stochastically searching DNA sequence space for genomes that would keep them around for evolutionary time are just going to be complex. The fact that biologists tend to be skeptical of the physicist's approach of building "simple" models to gain understanding in a "bottom-up" approach is well founded, because they have decades of experience as a field finding that the simplest explanation just wasn't the one that stood up to more experiments.
If you've made it this far somehow, you might be wondering why I'm writing this? I guess it upsets me that so many of Eric and Peter's valid criticisms of academia (the fact that tenure is a pyramid scheme, the perverse incentive structures, etc) are mixed with these grandiose ideas about how much smarter they must be than people in these other fields, since those fields are "moving so slow".
Hopefully someday I can come back and rewrite this into a guide: "how to be a good biologist for dummies physicists". But for now I guess it will remain a rant about the pitfalls of pontificating about a field you know nothing about.
And why? Recent polls show that scientists are largely still trusted by the American public. However, dive into conversation with anyone in the "mistrusts science" camp, and you'll quickly see that the internet age has led to an erosion of trust in science that would have been unfathomable to the generation that welcomed the atomic age.
While this eroded trust has serious societal consequences, I would challenge scientists to restrain themselves from casting aspersions simply because somebody answers "no" to a question like "do you, overall, trust the scientific process to produce reliable conclusions?" After all, even among scientists, this statement needs to be heavily qualified to be agreed with. Most scientists, in private, would admit that the scientific process is only right "eventually", or "most of the time" at best.
We hesitate to speak up about these nuances in public forums (or to aunt Betty on Facebook) because we know that any concession that science can produce bad results might be used as ammunition to not vaccinate children (or to justify all of the money spent on healing crystals).
Instead, when people make legitimate complaints about headline whiplash, we tend to claim that those effects are just due to reporting of "bad" science, or "preliminary" results. We attribute the public's frustration to the replication crisis, or to bad journalism. Or maybe we complain that the public simply does not know how to judge their sources of information.
But we rarely let ourselves admit that the process of science is imperfect, and that it often produces quite bad results.
We admonish these people for not trusting science, and in the next breath we complain about how so many papers published in Nature, Science, and Cell are full of just-plain-wrong results or conclusions. We complain that people don't believe us when we say that our climate models will still have the same predictions tomorrow, while being fully aware that they do not have any of the resources required (nor the time) to actually verify that this is true to any satisfying degree.
If you're a scientist right now, you might already be cringing even. Scared that this blog post will stray too close to dangerous waters, where my words might be misinterpreted by those seeking to denigrate science.
In this environment, it is easy for an outsider to see science as nothing but another religion trying to be sold to them. Science is the new scripture, and scientists the new priests. We are meant to trust what they say, and where we find inconsistency, we should understand that under further reflection, we would find that no inconsistency actually exists. Every time we blaspheme or dare challenge this new scripture, its priests disparage us and call us heathens, a blight upon society. They force reconciliation or exile. And so, people come to feel like they are not meant to understand science, but to simply believe it.
Clearly, if this is the impression that a person has received about science, then there is a fundamental problem in how science has been communicated to them. Many people have proposed that the solution is simply to more carefully and explicitly communicate uncertainty in scientific results.
But I think the problem runs deeper than uncertainty. It seems to me that, as a community, we lack a cohesive language with which to talk about different kinds of scientific results. You don't need to make a statistical statement to understand that building a laser trap to test predictions about entangling electrons is different in kind than measuring IQ and trying to make predictions about people's behavior (even though the error bars might appear to be of similar size!). Our intuition that these predictions have different levels of trustworthiness doesn't represent different levels of uncertainty, it represents an understanding that these are totally different types of activities.
And the dividing line is not between the social and "hard" sciences either! The hard sciences are chock full of purely statistical studies, such as GWAS studies that map out every gene that correlates with this or that disease. While genetics is a "hard" science, these results are not going to be as robust as a double-blind, longitudinal study on the effects of various evidence-based interventions designed to, for example, help traumatized children self-regulate (a "properly" scientific investigation).
The scientific community already internally uses various colloquialisms to classify different types of scientific inquiry by what their "model space" looks like:
In what follows, I hope to present an accounting of this language, along with recommendations on when each type of science is useful, and how much each type should be trusted.
I hope that with this more nuanced language, we can fearlessly admit that scientific results can be horribly, dangerously wrong, without jeopardizing our ability to speak authoritatively when it matters (climate change, vaccination, etc). Because what matters isn't building people's allegiance to the some new religion of science, it's giving them the language to understand how scientific results should be interpreted, so that they can make their own judgements about how this means they should act.
You'd be hard-pressed to find a working scientist that doesn't have a personal answer to this question. If they don't have it penned into words, they surely have years of accumulated intuition that they can quickly use to decide whether something is "good science", "bad science", or "not science at all" (depending on how opinionated they are, they might even be willing to eschew the middle category altogether!)
However, you'd be equally hard-pressed to find a conference or scientific forum where two scientists aren't arguing about exactly whether a particular result is or is not "good science". I have always felt that these conversations tend to largely involve people talking right past each other. Sure, there are cases when the entire room agrees that somebody has not done good science. However, it is far more often the case that the real issue seems to be that different people simply have different approaches to "science". After the references to Popper and Hume are over, and the participants have stopped comparing their personal scientific process to the development of the Standard Model, it always seems that both parties end up agreeing that everybody's approach is important (except for the social scientists, they never get to be in the "in" group).
I whole-heartedly believe that this is because these conversations largely boil down to people trying to pitch (or defend) their particular type of science as being the "one true definition" of science. If people had the language to more easily admit that the types of activities they are doing are as different as night and day (often equally valuable) without having to defend them as living up to some arbitrary standard of "true science", I think we'd all waste a lot less time at conferences.
In any case, it makes the most sense to follow my diatribe against people who try to "define" what science is with a definition of science:
Hopefully this is a sufficiently abstract (read: useless) definition that nobody can argue against it. It says nothing about what those strategies are, nor does it even mention experimentation! However, "predictive model" is quite a loaded word here, so it makes sense to unpack what is meant.
By "model", I tend to mean a mapping between observables and mathematical objects. However, I don't mean that I require the "model" to be written down in the conventional language of early 21st century mathematics, I merely want whatever language is used to describe the observables to be unambiguous enough to allow you to draw clear, logical conclusions about the observables. Some examples:
By "predictive", I mean something very subtle (because I don't think "causality" is really important to science at all, more on that below, I promise I'm not crazy). For a model to be "predictive", it merely needs to express a relationship between different observables that we expect to always be true. For example:
I guess it makes sense to explicitly compare my definition of "prediction" with the common usage of the word "counterfactuals" within the philosophy of science. In my opinion, this is an unnecessarily supercilious word. Basically, a model is predictive if it can take some information about how the world is and predict some other information about the world. Once one has a predictive model, predictions can be made based on actual observations, or else the inputs to the model can be drawn some other way, in which case the resulting prediction is called a counterfactual.
"But wait!", you might be screaming. "\(X\) satisfies your definition, but I most definitely would not call it science!"
I probably agree. But as I stated from the outset, I'm not in the business of defining what science is and isn't. I'm much more interested in describing the many things that people call science, so that we can have a language for discussing their relative merits. And if \(X\) satisfies my definition, I bet there's at least one person out there right now trying to pass it off as science.
The meat and potatoes. I'll be updating these lists as people suggest new entries to me, hopefully allowing me to apply the scientific process to my model of what science is.
The goals of people doing science vary wildly:
In every scientific study I have ever participated in has been driven by the three goals above: The exploration of trends, classification into invariants, and the logical study of how invariants interact to reveal novel emergent behavior.
However, the methods and heuristics that I have learned to apply when reaching for each of these goals are varied and overlapping, so it's worth listing them independently (as opposed to trying to associate each type of "scientific practice" with a particular "scientific goal"):
Okay, so those are the goals of science and its methods, but recall that my initial definition of science was
So largely what I've said above reduces to the statement that "predictive models" are just "trends" that we are confident enough to label "invariants", and that science is about uncovering these invariants and their consequences.
But that still leaves the most important part: what are the "strategies", in the definition above? What are the ways in which we choose what sets of invariants we care about, exclude those that are impossible or trivial, and construct the best possible predictive model?
It's just heuristics.
Thousands of years of heuristics that humans have either built into them, or discovered (and lost, and rediscovered) about what types of evidence should be considered trustworthy.
Here are some of the most well-known ones
So I've laid out some words that I like to use in conversation that describe the various goals of different activities which are all called "science" colloquially (and often, by the practitioners). But I have yet to make many value judgements about which parts are the most important.
All parts are important.
I hope that by merely laying out a framework for discussion, I have managed to avoid too much grandiosity. The entire scientific process is important, and scientists at all levels should be able to say "I'm a X!" proudly, where X is "data scientist" (searching for trends), "bottom-up modeling specialist" (e.g. mathematician doing physics or basic research), "exploratory experimentalist" (e.g. throwing money and sequencing at medical research problems and hoping something sticks).
What matters, from my perspective, is that the statistical results of the data scientist not be confused as having the same weight as fundamental results of e.g. an experimental biochemist.
While these are both important pursuits, they are different pursuits.
And if they are both called "science", then the public is right to not blindly trust all scientists, as different types will have different types of evidence for the statements that they make, not just different levels of confidence.